

Language Models: Size Matters
Making the case for small, hyper-personalized language models

Welcome to Fully Distributed, a newsletter about AI, crypto, and other cutting edge technology. Join our growing community by subscribing here:

Ah, the age-old question - does size matter? In the world of large language models (LLMs), the consensus has been that it does. Most of the mainstream excitement has been around the development of bigger and bigger models - and for good reason - increasing model size has been a major driver of performance. However, new research is emerging that challenges this notion, highlighting the importance of data quality and model fine-tuning.
In this essay, I will make the case for smaller models and why I think they will become the primary modality of human-machine interaction in the future.
Let’s dig in.
The Race Towards Bigger LLMs
The LLM arms race arguably started with the seminal paper “Scaling Laws for Neural Language Models” (Kaplan, McCandish, 2020) that demonstrated that model performance is driven primarily by just three factors - number parameters, size of dataset, and amount of compute used for training.

Scaling laws have been the driving force behind the "bigger is better" belief in LLMs.

However, as scale increased by orders of magnitude, so did the cost to train these models (adding up to tens and hundreds of millions of dollars). This had important implications:
Power concentration - only the most capitalized private tech companies can afford to participate in the development of these models
Proliferation of closed-source - easier to monetize and recoup the high upfront training cost, leading to issues around transparency, alignment, and security.
Lack of optimization - it is cost-prohibitive to iterate given that each run costs millions of dollars in compute, resulting in suboptimal model configurations.
The last point is an important one - models like GPT4 are incredibly expensive to train and fine-tune given their scale, and it’s impossible to run them locally.
But what if there was a better approach?
Small Models: The New Frontier
Recent research suggests that bigger isn’t always better when it comes to LLMs. A paper published by OpenAI (Ouyang, 2022) reveals that fine-tuning language models with human feedback can drastically improve performance without necessarily increasing the model’s size. In particular, OpenAI demonstrated that its 1.3B parameter model, InstructGPT, substantially outperformed GPT-3 (with 175B parameters) despite having 100x fewer parameters!
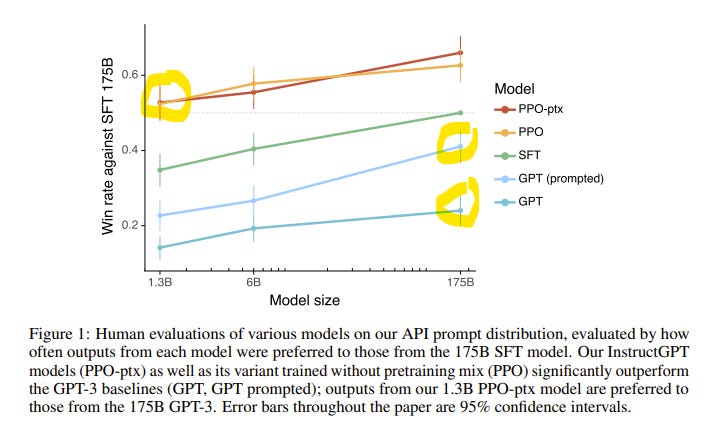
Small models with performance rivaling larger counterparts foster open access (lower compute costs → less barriers to entry → less oligopolistic dynamics) and promote hyper-specialization, enabling the creation of powerful industry-specific models that outperform generalist alternatives.
The most significant benefit of small models is edge computing, enabling highly efficient and agile models to run directly on devices like smartphones and laptops, rather than relying on cloud-based storage and expensive GPUs. This reduces both inference and, most importantly, training costs, paving the way for hyper-personalized models that continuously retrain on individual user personal data. Additionally, mobile edge computing enhances privacy, as data remains local, eliminating the need to send private or sensitive information to remote servers.
A clear winner here is Apple, which is most certainly developing its own small LLM optimized to run on its iPhone chips, thanks to their full vertical integration (they already released an open-source optimized version of Stable Diffusion image model). Android OS will likely also create its own powerful small models, but given the heterogeneity within the hardware it runs on, it is unlikely that this LLM will achieve the same level of optimization and speed as Apple.
Another interesting player to monitor here is EleutherAI - a research lab developing smaller open-source LLMs. This year they are expected to release a model with up to ~100B parameters, which should be more than sufficient for most use-cases given the appropriate reinforcement learning / fine-tuning.
These small, nimble models will become ubiquitous, seamlessly integrated into our personal devices - they will be a natural extension of our mind and we won’t even notice they are there. It will feel like magic.
OK, so small models are pretty cool. But what does this mean for the future of LLMs?
A Tale of Two Cities Models
I think a likely scenario is that we will have two types of models:
Ultra large proprietary models (e.g. GPT-7) trained on public data (internet)
Small optimized open-source models (e.g. LLaMA) fine-tuned on private data
A few ultra-large models (Microsoft’s New Bing, Google’s Bard?, etc. ) may provide us with general knowledge and reasoning about the world, while the small hyper-personalized models will run locally on billions of laptops and smartphones around the world. The sweet spot may lie in a delicate dance between these two approaches, where large and small models coexist and complement each other in various applications.
So what does this mean in terms of our path towards AGI? Perhaps we get there not through one jumbo model, but instead through an interconnected hive of myriads of hyper-specialized models.
Time will tell.
Conclusion
I hope by now I got you excited about new developments in the small model land. There are still many unknowns, but ongoing research efforts will continue to drive massive performance improvements and will unlock new possibilities.
In closing, I wanted to leave you with a few open questions to ponder about:
How does the optimal ‘interface’ change with model size? Is text the best modality for both?
Will various LLMs operate/interact with each other, akin to a hivemind? What does this architecture look like? How do we ensure maximum interoperability?
How will regulation affect the development of AI systems? Will governments be OK with a few big companies wielding so much power? Will they push/encourage the development of small open-source models?
Will consumers be comfortable sharing their private data with closed-source, proprietary, opaque AI systems?
Let me know what you think! DMs always open on Twitter @leveredvlad
If you enjoyed reading this, subscribe to my newsletter! I regularly write essays about AI, crypto, and other cutting-edge technology.
Great read!