Our AI Agent now costs more than human junior bankers...

Welcome to Fully Distributed, a newsletter about AI and its impact on business. Join our growing community by subscribing here:
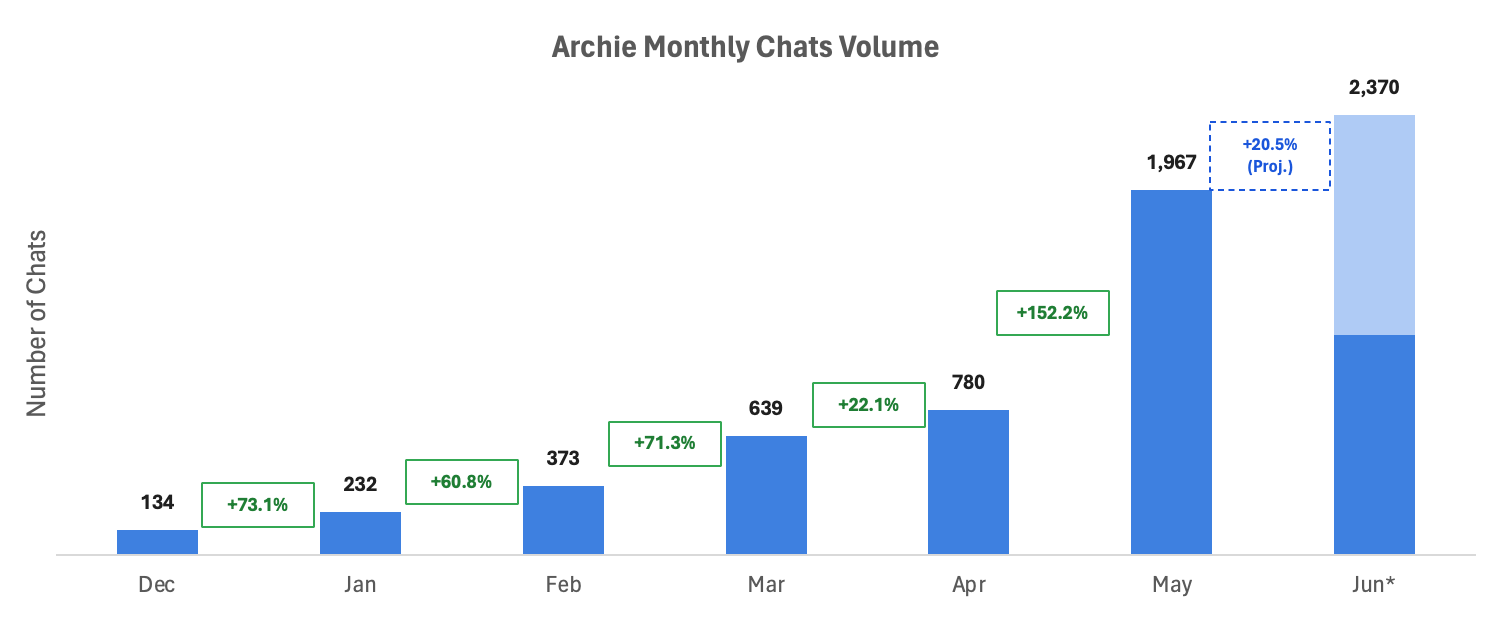
Since January, our internal AI agent Archie has 10x’d in cost - now ~$35K/month run-rate ($420K+ a year). That’s more than two full-time investment banking analysts.
Archie launched in December, and usage has grown from a couple hundred chats a month to ~2,400 (and each chat got longer, too). As we kept improving the AI harness around Archie, the product became increasingly useful to our investment bankers, and usage exploded.
While it is a great sign of product-market fit, it also made our token bill impossible to ignore.
In the early days we didn’t care about cost. We optimized for raw performance and watched Archie climb our (increasingly hard) evals from ~25% to ~75%. The math was simple — if the agent hallucinated or quoted the wrong number, nothing else mattered.
But when Fable 5 came out, my cofounder flagged that switching to it would eke out maybe another 3-4% on our evals, but it would also double our monthly cost to $70K+ - another two banking analysts, overnight. It was the first time we decided not to switch to a better frontier model because the incremental intelligence was not worth the incremental cost.
We’ve all heard about ballooning token costs in the enterprise, but seeing it inside my own “small business” - one with only five human investment bankers - made it look a lot more like a headcount decision. And I think millions of small businesses are going to face the same question: how much is truly frontier intelligence worth for the task at hand?
For us, the question moved from “What’s the smartest model?” to “What’s the right model for this specific task?”.
Investment banks already get this intuitively. Analysts do analyst work - models, decks, process materials - and MDs do MD work - origination, client management, judgement. It is not a good use of an MD’s time to format PowerPoint decks. Their time is better spent winning new business. And in many cases, they would actually be slower - and worse - than an analyst at that specific task.
We think AI will likely evolve the same way.
Frontier models will only be used for the hardest possible tasks - judgement, orchestration, complex reasoning and coordinating other models toward a common goal.
Smaller, specialized models - often open source - will do the more specific work where they can be both better and cheaper.
We’re already starting to see this. Harvey / Fireworks built a hybrid legal agent where an open model (GLM 5.1) ran as a primary worker and called Opus 4.7 as an “advisor” only when needed. The hybrid beat Opus end-to-end on both quality (18% vs 14% all-pass rate) and cost ($368 vs $954) - across the same 100 tasks. Similarly, fine-tuning Kimi K2.6 edged out Opus on their all-pass benchmark at roughly 11x lower cost.

Cursor is showing the same pattern in coding. Composer 2.5 is built on top of Moonshot’s Kimi K2.5 checkpoint and then trained for Cursor’s specific agentic coding workflows, delivering a ~10x reduction in cost for similar performance.
This feels like the direction of travel. Model routing will become the norm, with companies routing tasks across multiple models, each optimized for a specific capability, cost profile, and level of required intelligence.
A caveat on “real life” AI performance
AI model capability is wildly jagged.
Archie is amazing at taking 60 months of messy P&Ls and balance sheets and consolidating them into a single financial model with appropriate normalizations, add-backs, and adjustments. But it’s still not great at last-mile deck polish, formatting edge cases, or executing an actual NDA end-to-end.
That last mile still takes human labor. And as long as humans are needed to cover that gap, the model bill does not neatly replace headcount. In many cases, it sits on top of it.
This makes token economics even more important. If AI spend is additive before it is substitutive, companies need to be thoughtful about where they use frontier-level intelligence and where cheaper, specialized models are good enough.
I am very curious to see how Jevons’ paradox plays out over the coming year.
Demand for intelligence is effectively infinite, but the bill that comes with it is going to reshape how companies actually deploy that intelligence at scale.